Simulation modelling roadmap: beginning a digital journey
As we have mentioned in previous articles, simulation turns out to be an important decision support tool in SCM fields, where a 360-degree view of the possible impacts of decision alternatives is required.
In this article we will analyze the main phases inherent to the development of a model to support a generic SCM process.
Developing the model
The simulation model is created on a one-off basis as the model, which represents the real functioning of the supply chain (process) considered, will not be subject to substantial changes during its existence unless structural changes occur in the analyzed business context.
The creation of a simulation model for an SCM process involves 5 phases: requirements collection, conceptual design, model development, testing, scenario assesment.
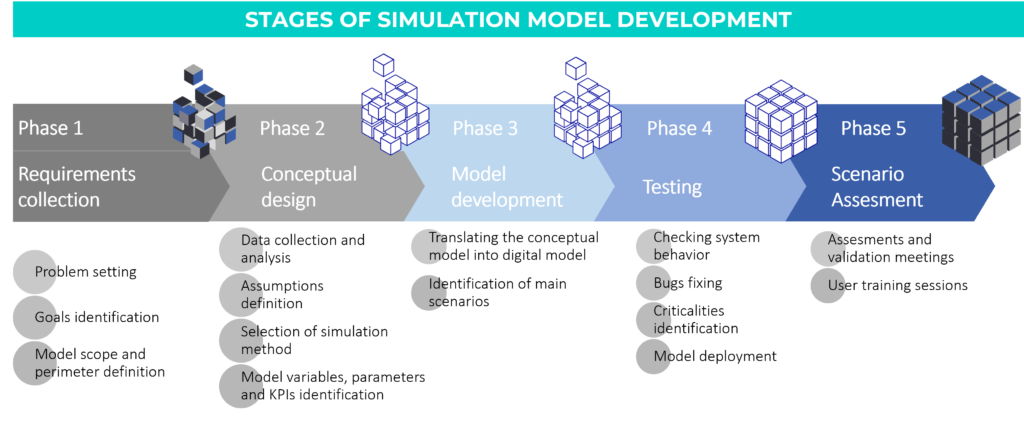
1. Requirements collection
Establishing the correct perimeter of the supply chain that you want to analyze and model is essential for the successful outcome and use of the tool. In this phase it is necessary to define the macro characteristic of the supply chain of interest.
Without the presumption of being exhaustive, below we report some areas of requisites collection.
1.1 Layers and actors of the supply chain
First of all is necessary to point out the number of levels, upstream and downstream,which need to be mapped in the model.
This activity requires an analysis of the main suppliers and customers, as well as a careful study of the existing production and distribution network.
As regards suppliers, it is necessary for example to understand which suppliers are critical and/or have the most impact on procurement decisions and possibly extend the scope also to more upstream levels (suppliers of suppliers).
Let’s think, for example, of a car manufacturer interested in developing a simulation tool to support the sales and operations planning (S&OP) process: an important choice could concern the mapping of microchip suppliers (highly critical in the value chain) and the mapping of the underlying market of semiconductors. This can be particularly useful for evaluating the effects that upheavals in the semiconductor market can have on the final automotive market, helping management to structure parallel sourcing or risk containment strategies to guarantee production continuity.
The same reasoning can be extended to number of downstream actors: in B2B contexts it could be useful to map customers’ customers to evaluate the impacts that changes in final product demand may carry on company operations. This obviously requires a in-depth knowledge of the mechanisms of demand propagation in the upstream levels of the supply chain as well as expected distribution of demand over time and its variation depending on characteristic market parameters.
In addition to the world of demand and supply, it is then necessary to carefully consider the existing distribution and production network: given the growing complexity of these networks, mainly due to the use of outsourcing of particular production phases (contracting) and distribution (use of logistics operators), it is critical to also monitor phases and processes in the model that are not directly under company control.
1.2 Products, components and raw materials
Mapping the master data of finished products, semi-finished products and raw materials constitutes another important input for the construction of the model.
Depending on the context to be modeled, it may be necessary to map the single finished product or serial production code (in the case of make-to-order productio), while in other cases it may be sufficient to limit the analysis to the product family (as often happens in traditional tools of S&OP).
The choice of the level of granularity in this case critically impacts the quality of the results produced by the model as well as the computational time necessary to develop the different simulation analyses.
Consequently to the definition of the products and components, it is also necessary to define which are the bill of materials (BOMs) to be considered in the model, in order to link the different product codes together according to supply-demand mechanisms.
1.3 Resources and capabilities
Usually in high-level decisions there is no need to consider the individual resources of the supply chain (such as vehicles, personnel, machinery, etc.) but it is preferred to aggregate their meaning in the term of capacity, understood as the sum of the availability of the individual resources.
Considering supply chain capacity as dependent on the constraints present is essential to produce eligible results and provide important points of analysis. While traditionally in strategic SCM processes, such as S&OP, the match between supply and demand is done with infinite capacity, in the simulation model it is already possible to define macro capacity constraints to consider the structural limits of the current supply chain.
Setting capacity does not only mean defining medium-term production capacity, but also considering other important capacity constraints that can affect the balance between supply and demand.
Let’s think for example about the distribution capacity of the network: in some cases it may be necessary to explain the storage capacity of critical nodes of the network to verify compliance over time and evaluate eventual temporary increases (for example through the rental of storage spaces). In other contexts, however, it could be advantageous to consider the limits of transport capacity, if the company has its own fleet of vehicles or relies on logistics service providers with limited capacity (think for example of the availability of maritime journeys and containers, seriously affected by changes and oscillations in recent years).
In summary, considering the different types of capacity (production, distribution, storage) can be particularly useful both for carrying out a correct balance between supply and demand and for evaluating in the scenarios the effects of potential risks impacting these macro-variables (think for example to the analysis of the impact of a fire in a warehouse, a strike in the transport sector, an interruption in a maritime course, etc.).
1.4 Planning policies
Defining the policies on which the company conducts its business can in some cases be a difficult abstraction of the way in which people, processes, technology and machines operate.
However, planning policies constitute the “mind” according to which the model carries out the calculations and simulations: if they are not clearly defined, there is a risk of obtaining results that are meaningless and devoid of applicability. Therefore it is good to spend time to analyze and abstract the main policies, which usually concern:
- market response strategy : make to stock (MTS), make to order (MTO), assembly to order (ATO), engineering to order (ETO), etc.;
- stock and supply management policies, such as: min-max stock, safety stock, fixed reorder point, fixed reorder period, etc.;
- production policies: continuous production, batch production, campaign production, JIT, etc.;
- transport policies, which are composed of: transport route (water, road, rail, air), FTL/LTL cargo, incoterms, etc.
It is clear that these policies may or may not be generalized for the entire product range: in practice it is often necessary to segment the same policy according to the reference family or product line.
Once defined and modelled, the planning policies will allow the model to simulate company performance according to the management perspective currently adopted; they will also allow decision makers in the SCM process to choose how to set important levers to achieve the results expected in the future (for example by changing inventory and/or transport management policies).
1.5 Risks and events
As already mentioned, the creation of a simulation model capable of replicating the functioning of a supply chain enables the possibility of being able to evaluate the impacts of particular events (risks and/or opportunities) on the performance of the supply chain.
This feature is particularly innovative compared to traditional decision support solutions, which usually limit themselves to varying the input data (forecast) to determine feasible production and sales plans. With simulation, however, it is possible to define a list of the main events that can significantly impact the supply chain and create different scenarios to evaluate the effects from an integrated perspective.
For example, for an international supply chain it could be useful to consider the risk of closure of some routes (i.e. some branches of the supply chain) following particular upheavals, temporary or permanent, in the economic context. On the contrary, for a short and local supply chain it could be useful to consider the effect of possible staff strikes that may occur in key nodes of the network.
Obviously, the clarification of the risks/opportunities that the model must be able to grasp and consider must be made as soon as possible in the requisitioning phase, in order to identify the links between exogenous variables (the risks) and those specific to the system (for example the capacity production, the forecast, the transport network, etc.).
For purely illustrative purposes, we report a non-exhaustive list of the main events that can affect a supply chain, which for convenience have been divided into exogenous risks (and therefore of a more macro-economic nature) and endogenous risks (more linked to the supply chain considered).
Exogenous events | Endogenous events |
|
|
From what has been said so far, it clearly emerges that the phase of collecting and defining requirements is crucial for the correct development and use of the simulation model. It is therefore a good idea to dedicate the right amount of time to analyzing the requirements and prioritizing them, as they will constitute the framework on which the simulation model will be created.
Obviously, depending on the size of the project perimeter, this phase can be carried out in a short time or, on the contrary, it can involve various professional figures and therefore take up a longer period of time.
Once the requirements have been collected, schematized, validated by the owners and confirmed by the solution developer (in terms of representability in the model), they will constitute the baseline on which to verify the progress of the model’s development as well as its actual capacity to respond to the information needs of decision makers.
2. Conceptual design
In the second phase of model development, requisites must be traduced in functional scheme of the model. In order to do so, a detailed analysis of available data and required assumptions must be carried out, ending in the final design of the model.
2.1 Data collection
Depending on the type of application, the data used by the model can vary significantly, therefore before starting the development it is necessary to identify and analyze the input datasets.
Without dwelling too much on aspects of data science that are beyond the scope of this article, we can briefly list the main steps to be carried out in this phase:
- Identification of data sources: it is necessary to understand which and how many data sources must be used to feed the model. This is a very delicate activity: as the number of data sources to be connected to the model increases, the complexity relating to the integration of such data increases too. For this reason we tend to use the principle of parsimony when selecting data sources, trying to integrate into the model only the essential databases that constitute its dynamic inputs (such as sales and/or forecast data). The connection to more “static” datasets, such as master data (products, customers, suppliers, facilities, etc.), can in some cases be avoided and replaced by a copy of the dataset made at a specific moment and perhaps re-scheduled with a fixed frequency in order to update the model with a certain periodicity. Other data, however, can be inserted “manually” into the model without needing to be connected to an external source as they are considered as parameters of the analyzed system (think for example of the production rate of a machine, which is usually a standard value for each type of product made).
At the end of this activity, the types of data to be integrated into the model will have been identified (e.g. forecasts, production orders, transport missions, etc.) with relative support on which they are available (company database; database extractions in csv or similar; unstructured data; etc.) and update frequency (dynamic, periodic, manual). - Preparation of input data: before importing data into the model it is good practice to carry out data cleaning and data aggregation operations. The first category of operations concerns the cleaning of the datasets in order to prevent anomalous or incorrect data that may compromise the functioning of the model (examples of data cleaning activities may include: removal/replacement of empty values, elimination of duplicates, integrity verification of the data, etc.).
Data aggregation operations instead serve to consolidate the starting data in smaller temporary databases to speed up the flow of model operations and reduce its computational time.
Obviously these operations, which are often carried out on platforms external to the model, must be carried out consistently with the degree of detail required by the model (for example it could be useful to aggregate all the individual sales transactions in a daily sales database). Depending on the complexity and quantity of the data to be managed, the dataset preparation phase can be carried out with the help of an IT expert (for example for writing read queries from company databases).
Once the useful data has been identified and appropriately prepared to be imported into the model, it is necessary to understand how to use them depending on the objectives for which the model is created.
To better explain this concept, we can consider data as information composed of a value and the related unit of measurement, to which multiple meanings can be associated:
- Physical meaning: these are the fundamental data of the model, without which it does not take a realistic connotation. They measure the flows in the model in quantitative terms and therefore have units of measurement referring to the object measured (e.g. per piece, per batch, …) or directly belonging to the decimal metric system (tons, kilometers, geographical coordinates, etc.). This elementary data can already be used for the optimization of some specific decision-making situations where it is not necessary to take into account the time factor (for example for the analysis of the center of gravity, used for the optimal choice of the location where to position a new facility).
- Temporal meaning: using simulation it is possible to keep track of the individual moments in time in which variables and KPIs change state (i.e. in which they take on a different value compared to the previous moment in time). This feature allows you to visualize the trend of the data over time and study its behavior, constituting one of the main advantages of simulation modeling.
The existence of data with physical and temporal meaning is sufficient to justify the creation of a simulation model.
However, these two meanings are often enriched by further information that can be associated with the physical data by means of multiplicative coefficients.
In these cases, we can for example introduce the following (optional) meanings:
- Economic meaning: by multiplying the physical data by the relative price/cost/value, it is possible to obtain considerable detail to build economic-financial indicators. This dimension is often fundamental in models as it allows decisions to be evaluated from the point of view of their profitability and generally provides an economic picture of the situation analyzed.
- Environmental meaning: for some types of data it is also possible to determine indicators relating to the environmental impact, measured under various aspects (e.g. equivalent CO2 emissions; energy consumption; water consumption; etc.). This allows decisions to be evaluated also from the point of view of their environmental neutrality.
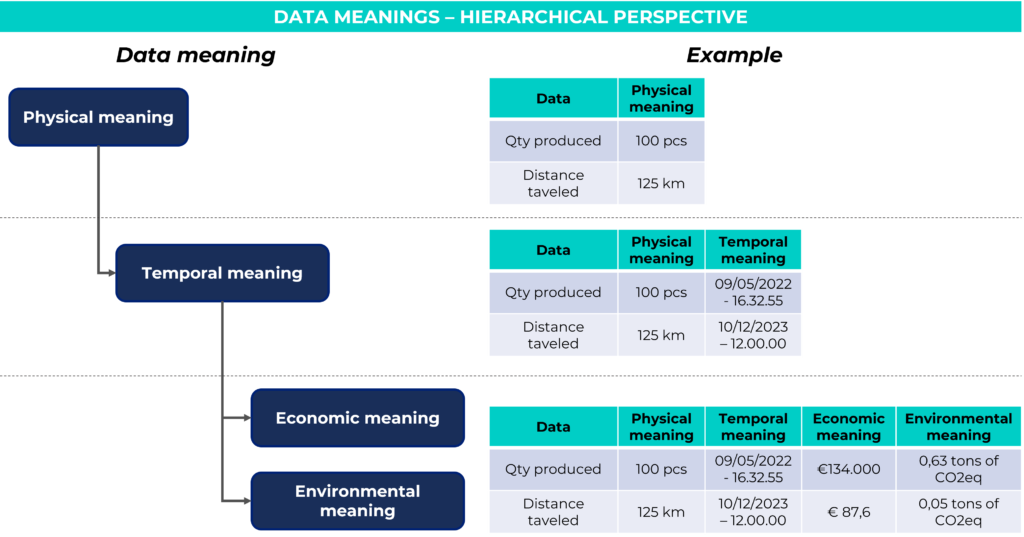
Depending on the type of application, the simulation model may need to generate data with different meanings. This involves a careful analysis of the information available, to verify whether it is possible to appropriately calculate all the indicators of interest.
Often this last analysis highlights situations of anomalies or lacks of important data and parameters, so it will therefore be necessary to develop hypotheses to guarantee the realization of the model.
2.2 Validation of hypotheses
The formulation and evaluation of hypotheses is an absolutely necessary phase in any model: it serves to definitively limit the perimeter of the model before its implementation.
In this phase we proceed to list the different assumptions present in the model, inherent both to the operating logic (which is an abstract and simplified representation of reality) and to the data available. It is good practice to identify the “weaker” hypotheses or those that require more attention in order to test them later during the creation of the model.
While the formulation of hypotheses must facilitate the process of simplification of the model, on the other hand it must also consider the requirements expressed previously.
This dual aspect therefore requires a careful analysis of the hypotheses identified to verify that they do not impoverish the model too much but rather that they facilitate it in representing the aspects of reality that are of interest to the decision makers/users of the model. Usually the list of hypotheses is reviewed with various actors involved in the project to verify that they do not violate the business requirements (e.g. sector experts, process owners, managerial figures, etc.).
The hypothesis validation phase then constitutes also an excellent starting point for clarifying the limits of the model and identifying potential directions for improvement.
At the end of the design of the model, the set of requirements, data and hypotheses constitutes the basis on which to develop the model.
3. Model development
The development phase concerns the actual creation of the model through the use of specific software based on object-oriented programming logic. The model developers will begin to create the structure starting from the fundamental requirements and then subsequently enrich it with secondary requirements and hypotheses.
Clearly this phase is the one that usually takes up the most effort in the project and involves the coordination of one or more figures expert in modeling. Typically in a supply chain modeling project of medium complexity, model development is a phase that accounts for between 50% to 70% of the total project effort.
In this phase it is particularly important to carry out localized tests on specific functions of the model to verify that it meets expectations and to correct any modeling errors as soon as possible, often generated by conflicting requirements.
The testing of individual parts of the model also allows to highlight any points of attention requiring in-depth analysis that may not have been taken into consideration in the previous phases. This possibility, typical of simulation modeling applications, is enabled by the fact that the model allows adopting an integrated vision of how all the variables involved contribute to determining the results. This allows the decision maker to change point of view and grasp counterintuitive aspects of particular situations.
In general, the development phase is carried out according to an agile approach, so it is preferable to create subsequent versions of the model by releasing certain feature packages from time to time. This approach, contrary to the water-fall one which sees the model usable only once all the developments have been completed, allows the iterative testing of the functionality and the modification of the modeling logic on-the-go, significantly reducing the time and effort associated with changes/additions to project requirements.
4. Testing
Once the model has been completely developed and integrated with the appropriate databases, a total functional testing phase follows to verify its adherence to the expressed requirements.
Using tests can be useful to review the less robust hypotheses of the model and test alternatives to correct the quality of the proposed results.
The tests are often carried out using historical datasets for which the relevant indicators (results) are available: this allows us to verify how faithful the estimates provided by the model are in respect to the final data available, and to eventually predict corrective actions.
Once all the tests have been passed, the model is ready to be released, i.e. to be delivered to its end user(s).
The release usually includes a training phase for users of the model to transfer knowledge relating to:
- operating logic of the model
- levers that can be used for the creation of different scenarios (usually proposed in appropriate interaction panels between model and user)
- dashboard for viewing results
5. Scenario assesment
This last phase deals with model usage, therefore it completely depends on project objectives.
It is possible to generalize the purpose and use of the model in the following alternatives:
- Use by professionals for conducting one-shot/recurrent analysis and definig directions and strategies of improvement
- Use by company users for supporting daily activities
In any case, the development of scenarios and the exploitation of different simulation runs are usually common activities for exploiting the model developed.
For a possible classification of model use inside SCM processes, please refer to the next article.
01
Problem solving in supply chain processes
Problem by problem: Analytical methods and Dynamic Simulation compared
02
Dynamic simulation as decision support
How to choose the right simulation methodology for a tailor made approach to reliable data-driven decision
04
Skills and technologies
Learn about the skills and technologies involved in this cutting-edge technology
06
Applying Simulation to the S&OP process
MRP, Scheduling, and in between Simulation Modelling: discover how